

4 min read

Text messages are a significant part of communication in today's world and one absolutely not to overlook as part of the eDiscovery process. In this two-part blog, we'll discuss the different methods used to show text message conversations in eDiscovery review, whether they are forensically sound, and how to create an accurate visual display to show text message conversations.
Text messages can be hard to preserve, review, and show in court. After repeatedly navigating these challenges, we've written this two-part piece on how to handle some of the unique issues presented by these communications.
Why Can't It Be Like Email?
A typical question about viewing text messages in eDiscovery is, "why can't it be like email?" It is very similar in many ways since a message is sent to someone, is from someone, and contains content and perhaps attachments.
But here's the difference - email follows an accepted set of standards across all manufacturers of email software and servers. They all build from a base set of metadata in the email header (or SMTP for the tech-oriented among us). Thus, if you have a .eml or .msg file, or a .pst or .mbox containing email, those messages can be de-duped, threaded, and normalized among each other regardless of the tool used to collect, process, and produce the data. There might be slight differences in an email production based on the imaging software used to create it, such as a native app like Outlook or an embedded tool within an eDiscovery program.
Not so for text messages; there are differences in the apps and how they store the data about a message. Some pieces of data may be the same, but unlike email, they are not stored similarly by all apps and devices. For instance, a phone may identify an incoming text message with a stored contact from that phone, but another device receiving that same text message from the same number may have a different stored contact name. Phone numbers from senders and recipients must be extracted to normalize the parties in a communication string. In email, this is trivial since the data is stored in a standard form in the email header, but there is no such standard header in a text message. It is simply the parties and the content with no additional metadata.
Another detail to note, the dates and times across text messages are generally not the same for the sender or all the recipients, whereas email has a common sent date and a variable received date.
Data Storage and Extraction
Collecting, processing, and reviewing text messages are complicated by the underlying differences in how data is stored and what information is kept. When collecting and preserving mobile devices, data extraction takes place from a specific phone rather than generating an exact copy of the information from a computer. The phone restricts direct access to the stored data, while a hard drive allows for copying.
Mobile data can be extracted with programs like Cellebrite in a logical or advanced logical fashion. Each of these extractions may contain some of the same data but not all of it. When loading multiple extractions into a review tool, there may be several copies of the same text message that can't be automatically de-duped. The same thing may happen if you combine extractions from two different tools.
For the same reasons, it is challenging to de-dupe mobile data, and it is difficult to create conversations or threads of text messages as they appear on the original devices. Unlike email, there is no thread tracking mechanism built-in. The most common approach to gain a uniform visualization of text messages across disparate devices is to treat each message as an individual document, each of which should have at least a date and time, a list of parties, and the content of the message. That is how the data is stored on the device; it is not stored as a conversation.
Review Challenges
Reviewing individual messages is very difficult because the context is missing. To simplify the review process, we apply advanced tactics processing the data in an offline tool to de-dupe and create threads based on parties included in a given message. However, some of those threads or conversations can be extremely long, sometimes even spanning several years, unlike email threads which are typically much shorter.
Once you combine individual messages into a thread, you lose the ability to easily find an individual's message using search terms. Some review tools have the ability to display text messages similar to the bubble format you see on a phone or tablet, but most treat each message as its own document. So, what's the solution, especially with some attorneys requesting a PDF with the conversation in bubble format? There are ways to create this with all the forensic data from a tool like Cellebrite (example screenshot below), which you can then load into a review tool.
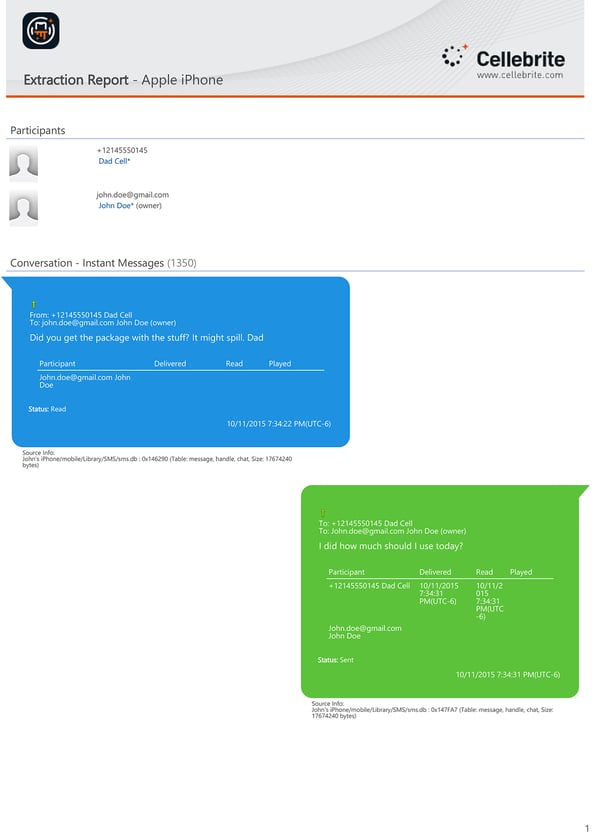
Viewing a conversation among three or more people in a text group on Android Messages, Apple's iMessage, and the messaging app Signal, each conversation will appear differently, may have different times, and could even show the messages in a different order. Messages will look different to a phone's user at a base level in terms of colors, fonts, and other graphical elements. Everyone is accustomed to a bubble on the right for sent messages and a bubble on the left with received messages. Different apps may include contact photos, contact names, emojis, or a message read indicator. The variations make it difficult to standardize a conversation display for review or use in court.
Here's where we'll leave you for now, but blog post Part 2 will answer the question – are screenshots the solution? We'll address that and other thoughts on how to create effective text message demonstratives.
Related Posts
How to Properly Display Text Messages for eDiscovery Review (Part 2)
Text messages are a significant part of communication in today's world and one absolutely not to...
Metadata Remixed
This article was posted as original content on the ACEDS Blog and written by Gavin W. Manes.
...
Digital Forensics Saves the Day!
A digital forensics investigation can make an impactful difference in an otherwise "routine"...